Easy Problems That LLMs Get Wrong
Sponsor Slot
Seen by 1,000s Daily
Research
This research explores a collection of seemingly simple problems that consistently challenge Large Language Models (LLMs). Despite their impressive capabilities on complex tasks, these models struggle with certain basic reasoning challenges that humans find intuitive.
∑ Key Findings
- Identified 30 simple problems that challenge LLMs
- Analyzed patterns in model failures
- Compared performance across different models
- Explored implications for AI reasoning capabilities
∞ Research Impact
- Reveals blind spots in current AI systems
- Provides benchmark for reasoning evaluation
- Suggests directions for model improvement
- Highlights gaps between human and AI reasoning
Cited by
Research Visualizations
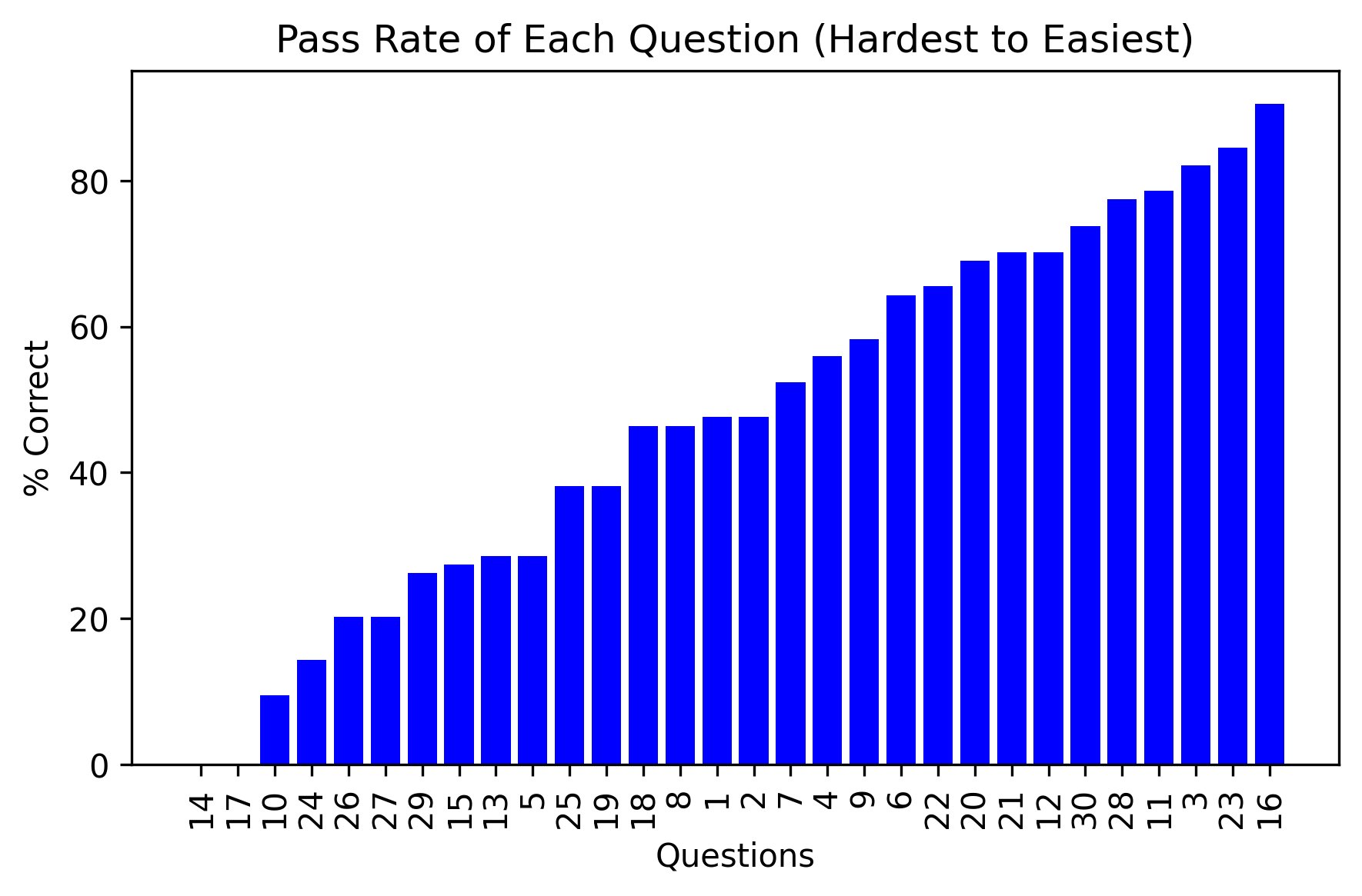
Question Difficulty Analysis
Pass rates for each question, ordered from hardest to easiest for LLMs to solve.
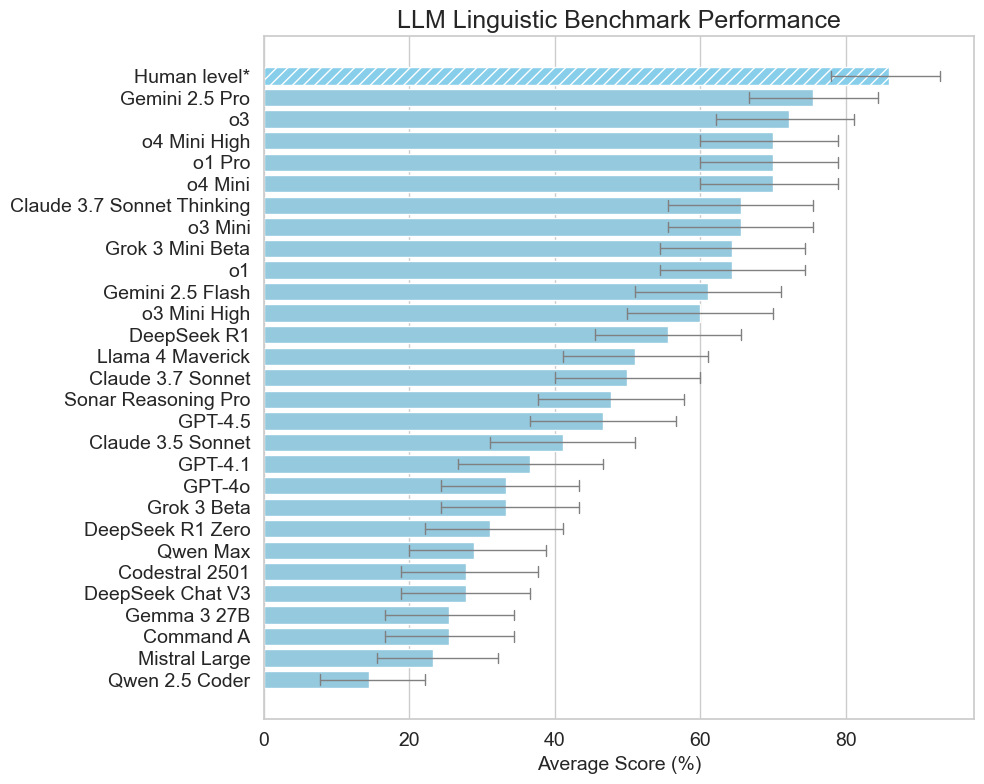
Model Performance Comparison
Benchmark results comparing various LLMs against human-level performance.
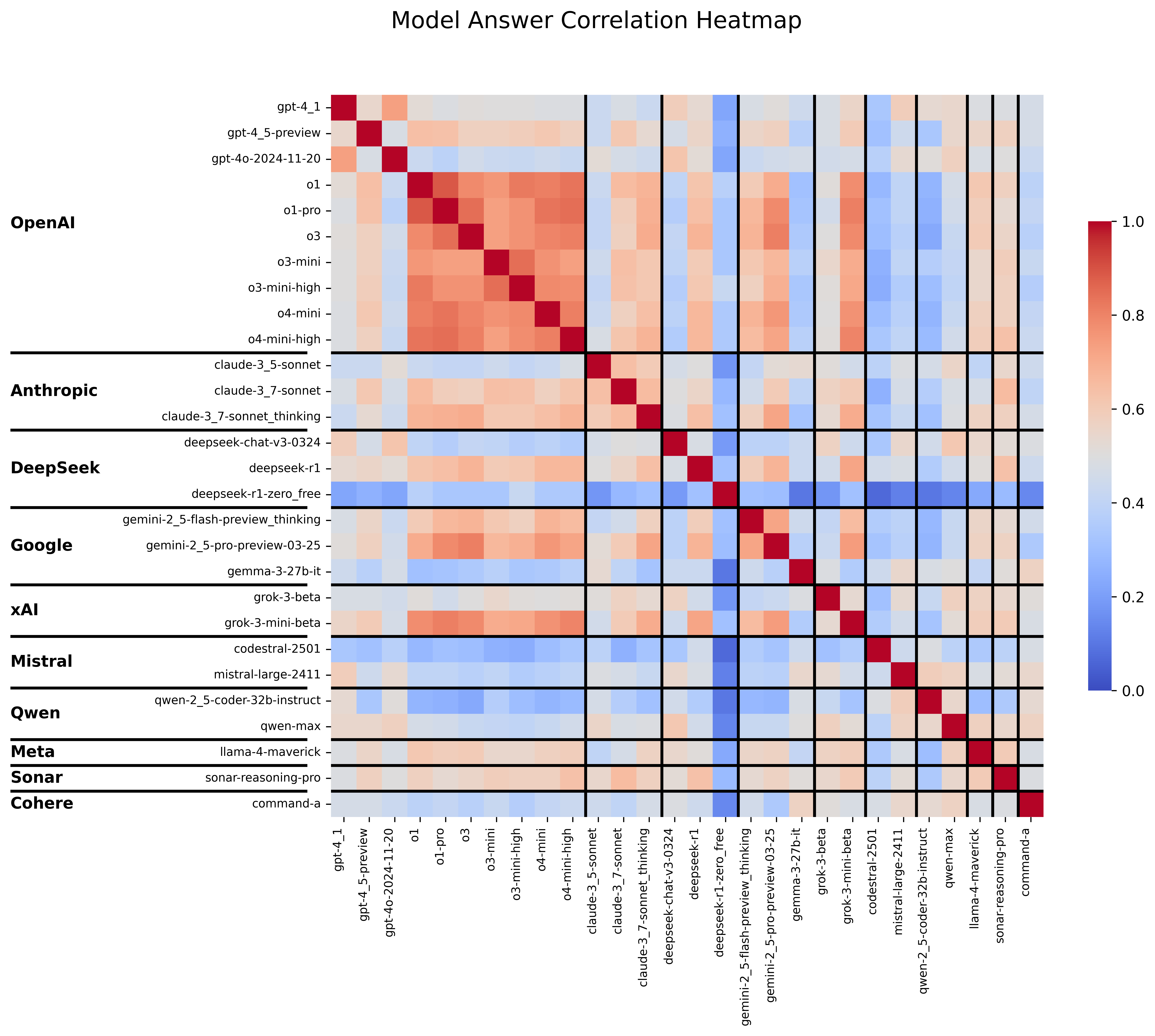
Model Answer Correlation
Heatmap showing how different AI models' answers correlate with each other.
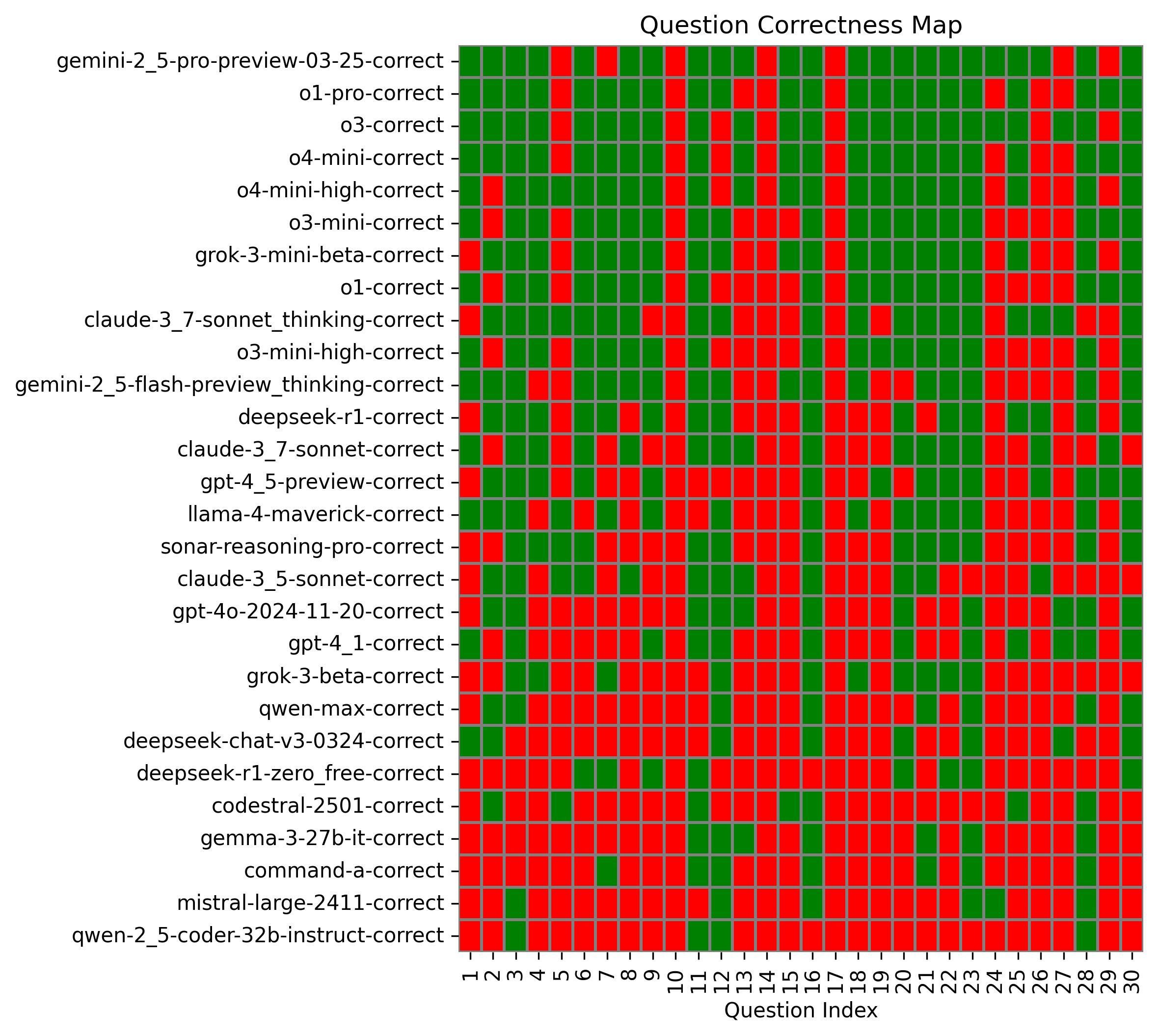
Question Correctness Map
Visualization of which questions each model answered correctly (green) or incorrectly (red).
Known LLM Limitations
1. Linguistic Understanding
LLMs have demonstrated difficulties with linguistic understanding, stemming primarily from the limitations of their intrinsic operational mechanisms. These models often misinterpret or overlook the nuanced meanings conveyed in human language. This results in inaccuracies or misjudgments when dealing with linguistic tasks or when parsing sentences that demand a deeper grasp of idiomatic nuances. [1]
2. Common Sense
A pivotal hindrance of LLMs lies in their absence of embodied experience, a factor Philosopher Hubert Dreyfus highlighted as crucial for the development of common sense in humans [2]. Unlike humans, who engage with the physical world through a rich palette of sensory experiences such as visual, auditory, and tactile stimuli, LLMs operate without sensory perception. This disembodied state restricts their capacity to learn the subtleties inherent to commonsense reasoning [3].
3. Contextual Understanding
AI's inability to handle context-sensitive reasoning was also critiqued by Dreyfus, which remains relevant to today's LLMs [4]. Correct reasoning is deeply intertwined with the ability to understand the often implicit context in which something relates.
4. Visual-Spatial Reasoning
Visual-spatial reasoning entails the ability to mentally visualise objects and understand their relationship within space. LLMs lack fundamental spatial awareness, so explaining the steps needed to navigate from one point to another in physical space or understanding the spatial configuration of objects remains a complex challenge for these models, showcasing a significant gap in a vital area of human intelligence. [5]
5. Mathematical Reasoning
LLMs express fragility in conducting simple mathematical reasoning, with word-based tasks that involve counting to ten often posing a significant challenge. While they can often provide correct answers to sophisticated mathematical queries, they fundamentally lack a rules-based counting system. They must outsource their calculations to other tooling, such as computer code or a calculator. [6]
6. Popular Science Knowledge
LLMs are particularly vulnerable to propagating and reinforcing inaccuracies found within their training data, including scientific misconceptions or outdated information commonly perpetuated online. An LLM's approach to generating content is heavily reliant on the frequency and presentation of information encountered during their training, which can lead to the uncritical replication of errors. This propensity not only highlights the limitations in their comprehension abilities but also underscores the importance of curating and updating the data these models are trained on to mitigate the dissemination of incorrect or misleading information. [7]
7. Relational Understanding
Understanding and interpreting relationships between entities, whether temporal, causal, or conceptual, is another area where LLMs face difficulties. Their interpretations often lack the depth and nuance of human understanding, as solving relational problems often requires an intuition that LLMs inherently lack. [8]
8. Logical Reasoning
LLMs are trained on an encompassing array of knowledge; however, this training approach does not guarantee proficiency in logical reasoning at inference time. Previous research has explored the logical capabilities of LLMs with mixed findings and suggests that LLMs can mimic reasoning up to a certain level but lack the reliability of human-like reasoning [9].
9. Overfitting
Overfitting is a well-documented phenomenon in machine learning, where models excessively adapt to the idiosyncrasies of the training data at the expense of broader generalisation. It is the belief that pre-trained models should excel in interpolating within the bounds of their training data but that extrapolation outside of those bounds is more difficult [10].
Linguistic Benchmark Question Types
Our research evaluates LLM performance across these distinct question categories, each designed to test specific reasoning capabilities.
| TypeQuestion Type | Description |
|---|---|
| Puzzle | Logic-type puzzles that mimic the structure of popular questions found online but differ significantly in one or more critical aspects that make the questions much easier for humans. |
| Spatial | Requires visualising the arrangement or relative positions of objects in space, such as determining the order or position of items or simple navigation. |
| Relational | Involve understanding and inferring relationships or hierarchies between objects, concepts, or entities based on provided information. |
| Counting | Simple numerical calculations such as counting to a maximum of ten or understanding quantities. |
| Linguistic | Tests the understanding and use of language, including forming sentences with specific constraints or identifying unique characteristics of words and phrases. |
| Popular science | Straightforward questions that test for common scientific and mathematical misconceptions. |
© 2025 | Research by Sean Williams and James Huckle